NVIDIA’s Inference Stack Depth Strategy
Part 2 of 3: The Co-Design Series

Jensen Huang isn’t buying inference companies. He’s buying stack depth.
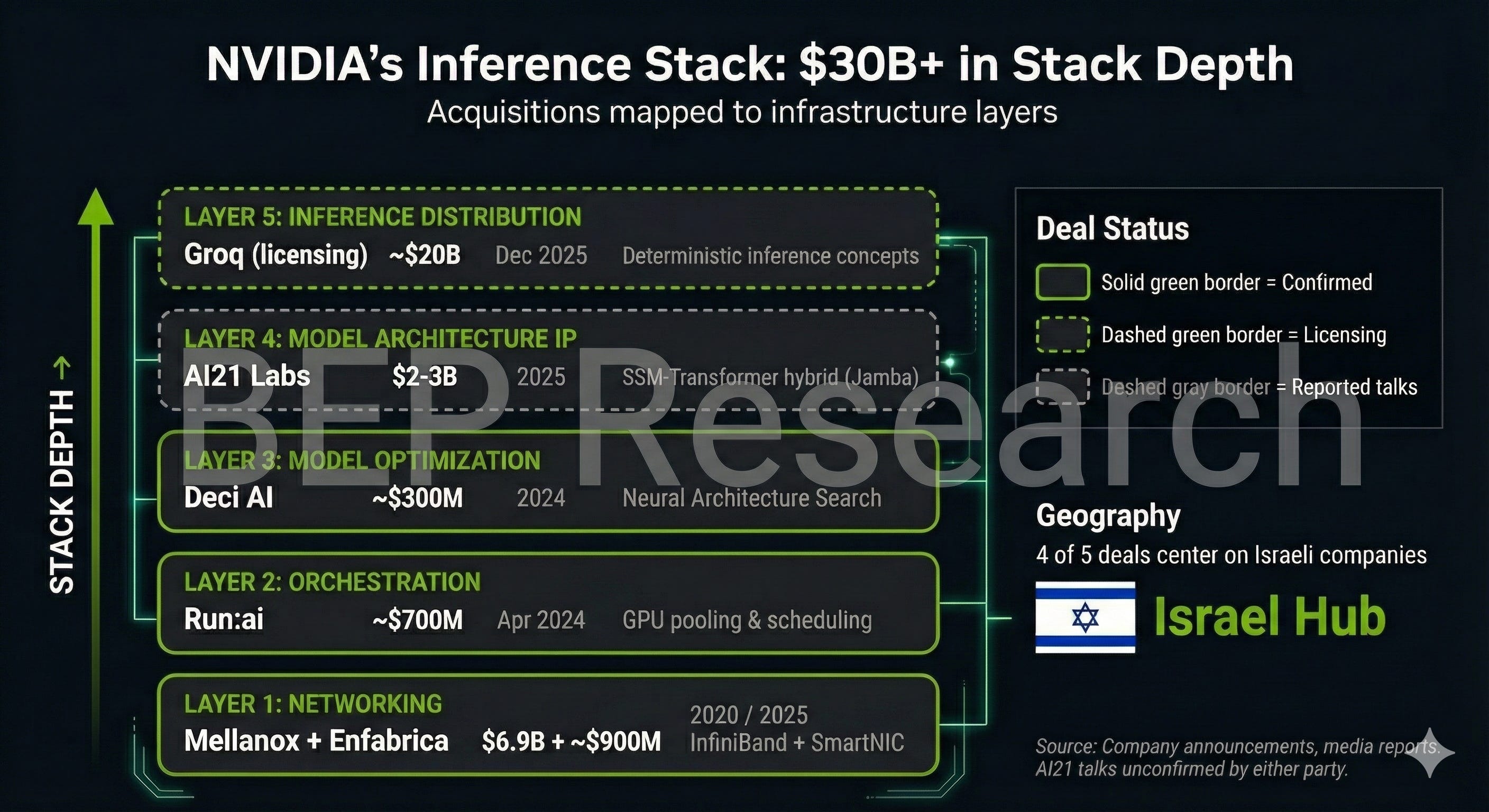
Since late 2024, NVIDIA has deployed over $30 billion in announced deals, licensing arrangements, and reported talks targeting the inference layer—not through traditional acquisitions alone, but through a mix of outright purchases, licensing agreements, and acqui-hires designed to absorb capabilities while managing regulatory scrutiny.
The pattern becomes clear when you map the deals to stack layers: networking, orchestration, model optimization, model architecture IP, and inference distribution. Each acquisition fills a gap. Together, they replicate what NVIDIA built with CUDA over 18 years—but compressed into months, targeting inference rather than training.
At CES 2026, Jensen showed what stack depth looks like when it ships: Vera Rubin NVL72—six chips co-designed as a unified system, delivering 10x throughput at 1/10th the cost. That’s not incremental improvement. That’s what happens when you control every layer.
The Stack Layers Framework
To understand NVIDIA’s strategy, think of inference infrastructure as five distinct layers:
Layer 1: Networking
How GPUs communicate within and across nodes. InfiniBand, NVLink, Ethernet fabrics. The plumbing that determines whether your cluster scales linearly or hits communication bottlenecks.
Layer 2: Orchestration
How compute resources get allocated across workloads. GPU pooling, virtualization, dynamic scheduling. The software that turns a cluster of GPUs into a fungible compute fabric.
Layer 3: Model Optimization
How models get tuned for specific hardware. Quantization, pruning, neural architecture search. The tooling that closes the gap between research models and production efficiency.
Layer 4: Model Architecture IP
Novel architectures that change the compute/memory tradeoffs. SSM-Transformer hybrids, mixture-of-experts, linear attention variants. The innovations that let you do more with less.
Layer 5: Inference Distribution
How inference actually gets served at scale. Deterministic latency, batching strategies, caching layers. The deployment patterns that turn model capabilities into reliable services.
NVIDIA’s CUDA moat was built on Layers 1-3 for training. Their inference strategy is now filling all five layers.
Timeline: The Deals
Here’s what NVIDIA has assembled, with deal structures clearly categorized:
Confirmed Acquisitions
Mellanox — April 2020 — $6.9 billion
Layer: Networking
The foundation. Mellanox brought InfiniBand technology that now underpins every DGX SuperPOD deployment. The acquisition gave NVIDIA control over the interconnect layer—how GPUs talk to each other at scale. DGX clusters with NVSwitch and InfiniBand integration achieve up to 2-3x higher throughput than commodity networking.
Run:ai — April 2024 — approximately $700 million
Layer: Orchestration
GPU orchestration software that pools, virtualizes, and dynamically allocates GPU resources. Run:ai lets enterprises treat GPU clusters as fungible compute rather than dedicated hardware. NVIDIA announced plans to open-source the software—extending it to AMD and Intel GPUs. This is strategic: embed NVIDIA orchestration as the industry standard, even on competitor hardware.
Deci AI — 2024 — reported at approximately $300 million
Layer: Model Optimization
Neural Architecture Search (NAS) technology that automatically optimizes models for specific hardware. Deci’s tools reportedly achieve 3-15x inference speedup while preserving accuracy. Combined with TensorRT, this creates an end-to-end optimization pipeline from research model to production deployment.
Licensing and Acqui-Hire Deals
Groq — December 2025 — reportedly valued at approximately $20 billion
Layer: Inference Distribution
This is the most revealing deal structure. Rather than acquire Groq outright—which would invite antitrust scrutiny—NVIDIA structured a non-exclusive licensing agreement with an acqui-hire of CEO Jonathan Ross and senior leadership. GroqCloud continues operating independently.
As I wrote in “Twas the Night Before Groq”, the deal maintains competitive optics while NVIDIA integrates LPU’s deterministic inference concepts into its roadmap. The structure suggests NVIDIA wants the technology and talent without the regulatory burden of eliminating a competitor.
But here’s the hardware play most people missed: Groq’s architecture bypasses CoWoS and HBM entirely. No advanced packaging bottlenecks. No memory supply chain constraints. NVIDIA now has IP to build inference-focused chips that sidestep the two biggest capacity constraints in AI silicon.
Enfabrica — September 2025 — reportedly over $900 million
Layer: Networking
Similar structure: NVIDIA reportedly hired Enfabrica’s CEO and licensed its SmartNIC/DPU technology rather than acquiring the company outright. Enfabrica’s fabric technology targets the network layer specifically for AI workloads—complementing Mellanox’s InfiniBand with Ethernet-based solutions for different deployment scenarios.
Reported Talks (Not Confirmed)
AI21 Labs — reported December 2025 — $2-3 billion range (unconfirmed)
Layer: Model Architecture IP
According to Calcalist and other Israeli media, NVIDIA is in advanced acquisition talks with AI21 Labs. The deal would bring Jamba’s SSM-Transformer hybrid architecture and approximately 200 employees with expertise in memory-efficient model design. As of publication, neither company has confirmed these talks.
The Israel Concentration
Four of these deals—Mellanox, Run:ai, Deci AI, and the reported AI21 talks—center on Israeli companies. NVIDIA now has over 4,000 employees in Israel and has announced plans for a 10,000-person campus.
This isn’t coincidence or talent arbitrage. It’s ecosystem cultivation.
Israel’s tech sector has deep expertise in the specific disciplines NVIDIA needs: networking (Mellanox’s InfiniBand heritage), systems software (Run:ai’s Kubernetes-native GPU orchestration), and NLP/model architecture (AI21’s founding team includes researchers from Google Brain and DeepMind).
By concentrating these acquisitions geographically, NVIDIA creates a self-reinforcing talent cluster. Engineers move between companies. Ideas cross-pollinate. The inference stack gets developed by teams that share context and relationships—exactly what happened with CUDA in Santa Clara over 18 years.
This is the CUDA playbook, replicated at the inference layer, compressed in time, and anchored in Israel.
CES 2026: Stack Depth Made Physical
Vera Rubin isn’t just a chip announcement. It’s the physical manifestation of stack depth. I covered the full technical breakdown in my CES 2026 analysis—here’s why it matters for the acquisition thesis.
The six chips announced at CES—Vera CPU, Rubin GPU, NVLink 6 Switch, Spectrum-X CPO, ConnectX-9 SuperNIC, BlueField-4 DPU—weren’t designed independently. They were co-designed as a system. Each silicon decision was informed by how it would interact with every other component:
Vera CPU exists to feed the Rubin GPU via NVLink-C2C at 1.8 TB/s
NVLink 6 Switch exists to connect 72 GPUs at bandwidth that matches their appetite (3.6 TB/s per GPU)
BlueField-4 DPU exists to extend memory beyond what HBM alone can provide (+16TB distributed KV cache per rack)
Spectrum-X CPO exists to scale beyond what electrical interconnects allow (800G silicon photonics)
This is what Jensen means by “extreme co-design.” And it’s why competitors face a challenge that goes beyond matching specs—they need to match system-level integration that took years and billions in acquisitions to develop.
Stack Depth in Action: The January 2026 Proof Point
If you want to understand why stack depth matters more than chip specs, look at what NVIDIA published this week.
Running DeepSeek-R1 on GB200 NVL72, NVIDIA’s January 2026 TensorRT-LLM update delivered 2.8x higher token throughput compared to October 2025—on the exact same hardware.

Same chips. Same memory. Same interconnects. The only difference: better software across the stack—disaggregated serving, enhanced all-to-all communication primitives, NVFP4 precision format, and multi-token prediction.
On HGX B200, the gains were even more dramatic. Enabling NVFP4 and multi-token prediction delivered 4x+ throughput over the FP8 baseline.
 to FP8 with MTP On (darker gray) to NVFP4 with MTP On (green), the curves continue to shift to the right, indicating more throughput at a given interactivity level and enabling higher peak interactivity.")
This is what stack depth looks like in practice. Competitors can match NVIDIA’s chip specs on paper. Matching continuous software optimization across networking, orchestration, model optimization, and inference distribution—quarter after quarter, model after model—is a different challenge entirely.
The acquisitions aren’t just about capabilities. They’re about velocity. Every layer NVIDIA owns is a layer they can optimize in lockstep with everything else.
What Competitors Must Do
NVIDIA isn’t alone in recognizing that inference requires vertical integration. But competitors face different constraints:
Google
Google epitomizes internal co-design. TPU v5p pods deliver 4 ExaFLOPS across 8,960 chips with JAX and XLA compiler designed alongside the silicon. Upcoming Ironwood (TPU v7) pushes further: 4,614 TFLOPS per chip, scaling to 42.5 ExaFLOPS per pod.
Critically, Google trained Gemini entirely on TPUs. They don’t need NVIDIA’s stack—they built their own. But this advantage is captive: TPUs serve Google’s workloads, not the broader market.
Amazon
Trainium 3, announced in late 2024, is AWS’s first 3nm AI chip: 4.4x faster than Trainium 2 with 4x better energy efficiency. Project Rainier—a 400,000-chip Trainium 2 cluster for Anthropic—signals Amazon’s commitment to owning inference infrastructure for its cloud customers.
Amazon’s challenge: building the software ecosystem. Hardware without CUDA-equivalent tooling limits adoption outside AWS’s most committed customers.
Microsoft
Maia 100 represents Microsoft’s vertical integration bet: a massive die (reportedly 820mm²) with custom Ethernet protocol and a software stack built on Triton. Their framing—”from silicon to software to systems”—explicitly acknowledges the co-design imperative.
Microsoft’s challenge: they’re earlier in the silicon journey than Google or Amazon, and still heavily dependent on NVIDIA for current Azure AI workloads.
AMD
MI300X with 192GB HBM3 and 5.3 TB/s bandwidth has won deployments at Microsoft Azure and Oracle Cloud. At CES 2026, Lisa Su introduced the “yottaflop” framing—a measure of computing power so vast it was previously theoretical. The 2026 roadmap shows MI400 with up to 432GB HBM4, plus “Helios” rack architecture integrating EPYC CPUs, GPUs, and networking as a unified system.
ROCm has narrowed the software gap significantly—industry estimates now put performance within 10-30% of CUDA for supported workloads, down from 40-50% historically. But AMD lacks NVIDIA’s orchestration and optimization layers. They sell chips; NVIDIA sells stack depth.
The Strategic Logic
NVIDIA’s training monopoly is secure—CUDA’s 18-year ecosystem moat isn’t going anywhere soon. But training is increasingly a hyperscaler game: Google, Amazon, Microsoft, and Meta build their own training infrastructure.
Inference is different. Inference is distributed across millions of deployments—enterprises, startups, edge devices, embedded systems. No single hyperscaler will own inference the way they’ve consolidated training.
This is NVIDIA’s opportunity: own the inference stack the way they own the training stack, but for the long tail of deployments that hyperscalers won’t serve directly.
The acquisitions make sense in this light:
Mellanox: control the network fabric
Run:ai: control the orchestration layer (and make it the standard, even on competitor hardware)
Deci: control the optimization pipeline
Groq concepts: absorb deterministic inference for latency-sensitive applications
AI21 (if completed): control memory-efficient model architectures
Stack depth creates switching costs. Once you’ve built your inference pipeline on NVIDIA’s orchestration, optimization, and deployment tools, moving to AMD or Intel isn’t just swapping chips—it’s rebuilding the entire stack.
The Portfolio Approach
One insight from the Semi Doped podcast deserves emphasis: NVIDIA isn’t pursuing a one-size-fits-all strategy. They’re building a portfolio of inference approaches.
The future isn’t “GPU for everything.” It’s workload-specific optimization:
Large frontier models: Vera Rubin with HBM4 at 22 TB/s bandwidth
Ultra-low-latency inference: Groq-style deterministic architectures for sub-millisecond response
Long-context workloads: BlueField-4 Context Memory Platform extending KV cache across racks
Edge and robotics: Jetson and specialized inference chips for physical AI
The TCO calculation changes based on workload. NVIDIA’s stack depth means they can offer the right solution for each segment—and capture value across all of them.
The Takeaway
NVIDIA’s inference strategy isn’t about better GPUs. It’s about owning every layer between the model and the user.
For competitors, the implication is clear: matching NVIDIA on silicon isn’t enough. You need the orchestration layer. You need the optimization tooling. You need the deployment infrastructure. You need the model architecture innovations that make your silicon sing.
The companies that recognize this—Google with TPUs, Amazon with Trainium, Microsoft with Maia—are building their own stacks. Everyone else is increasingly building on NVIDIA’s.
Next in this series: Part 3 examines the gap that none of these companies have filled: verification and control for agentic workloads. When you’re orchestrating thousands of AI agents, who audits the swarm? The unsolved problem that might matter more than silicon. Coming Friday.
If you found this analysis valuable, please share it—it helps more than you know. And if you haven’t subscribed yet, now’s the time. BEP Research will be moving to paid soon, and early subscribers will be grandfathered in. I’m committed to delivering institutional-quality analysis on AI infrastructure that you won’t find anywhere else.
Resources
NVIDIA CES 2026: Six Chips, One Platform, and the Extreme Codesign Era (BEP Research)
Twas the Night Before Groq: NVIDIA’s Surprise Licensing Deal (BEP Research)
Delivering Massive Performance Leaps for MoE Inference on NVIDIA Blackwell (NVIDIA Developer Blog)
About the Author
Ben Pouladian is a Los Angeles-based tech investor and entrepreneur focused on AI infrastructure, semiconductors, and the power systems enabling the next generation of compute. He was co-founder of Deco Lighting (2005–2019), where he helped build one of the leading commercial LED lighting manufacturers in North America. Ben holds an electrical engineering degree from UC San Diego, where he worked in Professor Fainman’s ultrafast nanoscale optics lab on silicon photonics and micro-ring resonators, and interned at Cymer, the company that manufactures the EUV light sources for ASML’s lithography systems.
He currently serves as Chairman of the Leadership Board at Terasaki Institute for Biomedical Innovation and is a YPO member. His investment research focuses on AI datacenter infrastructure, GPU computing, and the semiconductor supply chain. Long-term NVIDIA investor since 2016.
Follow on Twitter/X: @benitoz | More at benpouladian.com
Disclosure: The author holds positions in NVIDIA and related semiconductor investments. This is not investment advice.
At CES 2026, NVIDIA unveiled its six-chip Rubin AI platform, featuring the Spectrum-6 Ethernet Switch for high-efficiency, scale-out networking. This switch supports large-scale AI training and inference by delivering reliable, high-bandwidth connectivity across the Rubin system. More details are available here: https://www.naddod.com/ai-insights/spectrum-6-ethernet-switch-deep-dive-sn6810-102-4t-and-sn6800-409-6t-switch
I like smh here, long term. Somewhat extended but top 10 holdings all very good. Most have a solid purpose.